Industrial Challenge Vinci St Exupery Airport
This project was built during the Master MINDS M1’s Industrial Challenge with the Lyon Saint Exupery airport.
The project aims to build a strong solution to predict the flow of passengers in a daily and per flight manner to better adapt the necessary human ressources for the airport to work efficiently without negatively impacting the service.
In this project we were two teams of 4 peoples, each person working on specific part of the project. Some peoples worked on data mining and analysis on the airport’s dataset used to train the model, other peoples selected the best model and best solutions to improve the model, while other peoples worked on enriching the base data from the airport.
With prior experience on working with big data and conflict data, my role was mainly to build a pipeline that can be used to get external information about the world status. Thus, I will mainly talk about this.
The data sources
First of all, I looked for data that would be used by airlines, for example the closure of an airspace. For this, airlines usually look at what we call NOTAMs, these are very useful, but pretty complex to get historical data for free and even more for data around the world. Another point is that the NOTAMs give informations which are extreme.
What we want by adding external geopolitical risk data for flights is to help the model learn why some flights get less passengers compared to usual, the idea is to better model the few cases which do not follow the “usual” flow.
Another key factor is that we need historical and realtime data, thus we cannot use datasets like UCDP since it would not check the realtime constraint. We also found a very useful website named SafeAirspace, but this website sadly do not provide historical data, making it unusable. Still, it gives a good base to create a risk score, so I decided to use similar rules to calculate the risks.
To the best of my knowledge, the only data source checking both historical and realtime data is the GDELT project, which can be queried with BigQuery or by looking at the csv posted every 15 minutes.
Working on the data
The airport already uses BigQuery, thus I made the choice to keep using BigQuery, it also allows to perform queries very quickly, to make things easier for training, I made a download code that selects data up to a specific date (based to the oldest date we have) and pull only this data. The query also filters the events based on their codes to make sure we don’t download a dataset too big compared to our actual needs.
The dataset gets saved into Parquet files, one parquet file for one day, the downloading code can be re run everyday and it will only download the latest data, reducing the data usage of BigQuery but also the time used for download.
Then, most of the data engineering work was done in Polars, using lazyscan I was able to perform my firsthand operations, grouping the events into one event per country per day, keeping the most important event only. This lazyscan and from polars let me work on the whole dataset (all the files) while not exploding in memory, the transformation is still pretty fast (only a matter of seconds) on my laptop.
Then, we have to apply a second work, we need to modify the base risk score based on the information in the event, GDELT is a nice data source if we forget that its quality is, to be honest, pretty bad, there is a lot of incomplete informations, or straight up false classification. Still, we can mitigate as much as possible this to find a more realistic risk score.
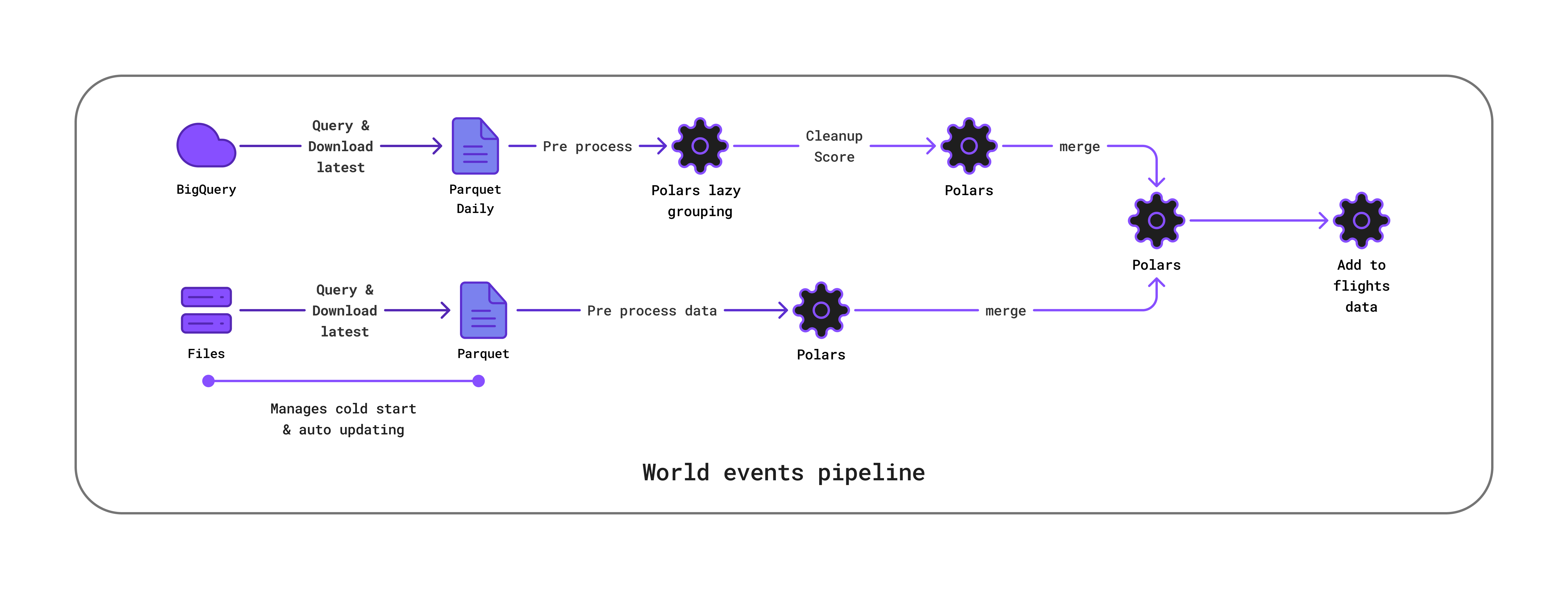
It is not perfect and would need an important rework, and maybe a much stronger pipeline, but with the quality of the data and the deadline, it was not possible to do much better while proposing a solution which does not consume too much data / computing power.
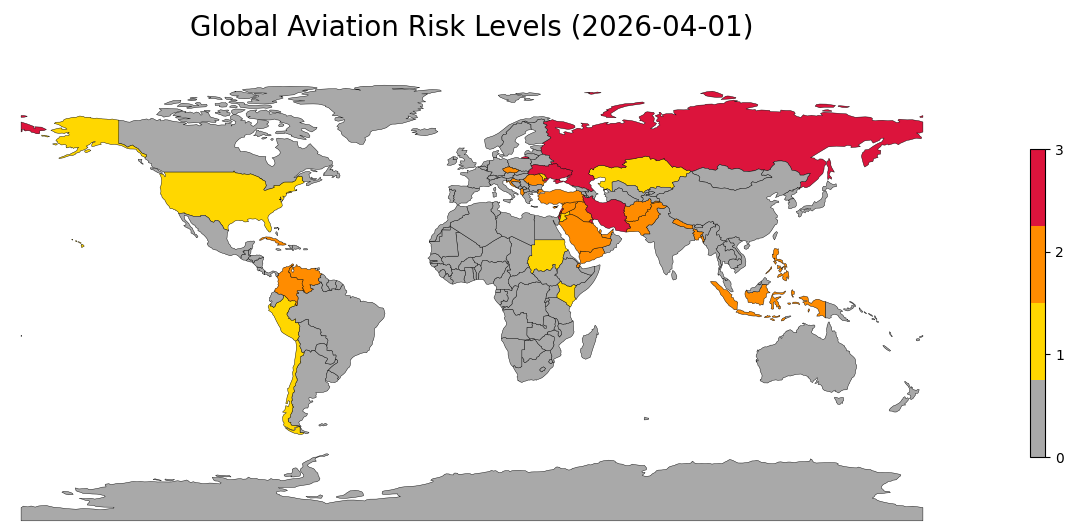
With this pipeline, we get the resulting map for the 1st of April 2026.
If you are interested about the code it is available here.
Be aware, the code for the conflict pipeline is in the brach conflicts here.
The other parts
This is not what I worked on, but here is an explanation of the other stuff. Thus i will talk very very quickly about it, since it, in fact, is not my work.
Some of the work on the data engineering end was to make features cyclical and calculate more representing temporal information, such as “in how many days will there be a day off from today” or “are we at the end of vacations?”. This improved alot the results for the models.
A temporal model was also trained and used to give better information to the model about the usual trends at the same period of the year, this gives better representation by looking at knowledge from the past and more context in terms of the overrall trend.
Lastly a hyper-parameter search was run on many model architecture, what was found is that the best architecture was XGBoost.
The results
Both teams were extremely close together, but the results where generally pretty good especially taking in account the time available (less than 2 weeks from the start to the day of the predictions submission).